Abraham Aroloye
Data Engineer - Web Developer - SEO Expert

I build data systems, not just scripts
I started as a self-taught web developer and over the years shifted my focus entirely to data engineering. What pulled me in was the challenge of building things that are reliable, scalable, and actually useful at a production level.
My background spans ETL/ELT pipelines, medallion architectures, REST API integrations, data quality enforcement, and containerised deployments. I think in systems. I care about idempotency, change detection, and making sure data is trustworthy before it reaches anyone downstream.
Right now I am targeting Analytics Engineer and Data Engineer roles where I can work with dbt, modern cloud warehouses, and teams that care about doing data modelling properly.
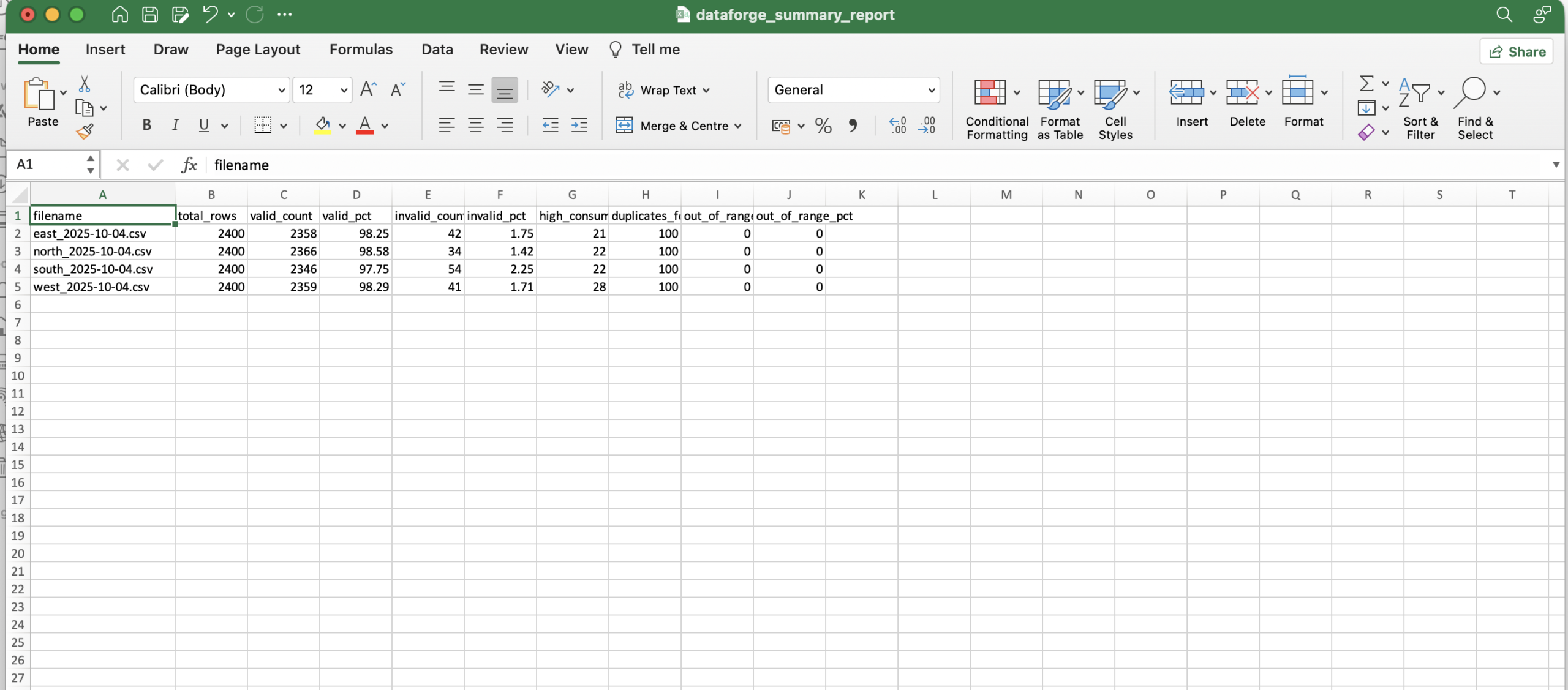
 End-to-end pipeline delivery: From API ingestion to transformed, tested, documented data in Snowflake Data quality enforcement: Great Expectations checks and SHA-256 change detection on every pipeline run Containerised & production-ready: Docker-based deployments with Airflow orchestration and webhook integrations dbt modelling with incremental strategies: Dimension tables, fact tables, tested models and proper documentation
End-to-end pipeline delivery: From API ingestion to transformed, tested, documented data in Snowflake Data quality enforcement: Great Expectations checks and SHA-256 change detection on every pipeline run Containerised & production-ready: Docker-based deployments with Airflow orchestration and webhook integrations dbt modelling with incremental strategies: Dimension tables, fact tables, tested models and proper documentation